Add Website Content to Your Chatbot
Import your website or help-center pages to give LiveChatAI a reliable, up-to-date knowledge base.
The crawler scans public URLs, breaks the text into context-aware chunks (AI Boost is always on), and trains your bot automatically—no manual copy-and-paste required.
Plan and Character Limits
Step-by-Step Guide
1. Open Data Sources → Add new → Website
The Website Source wizard appears.
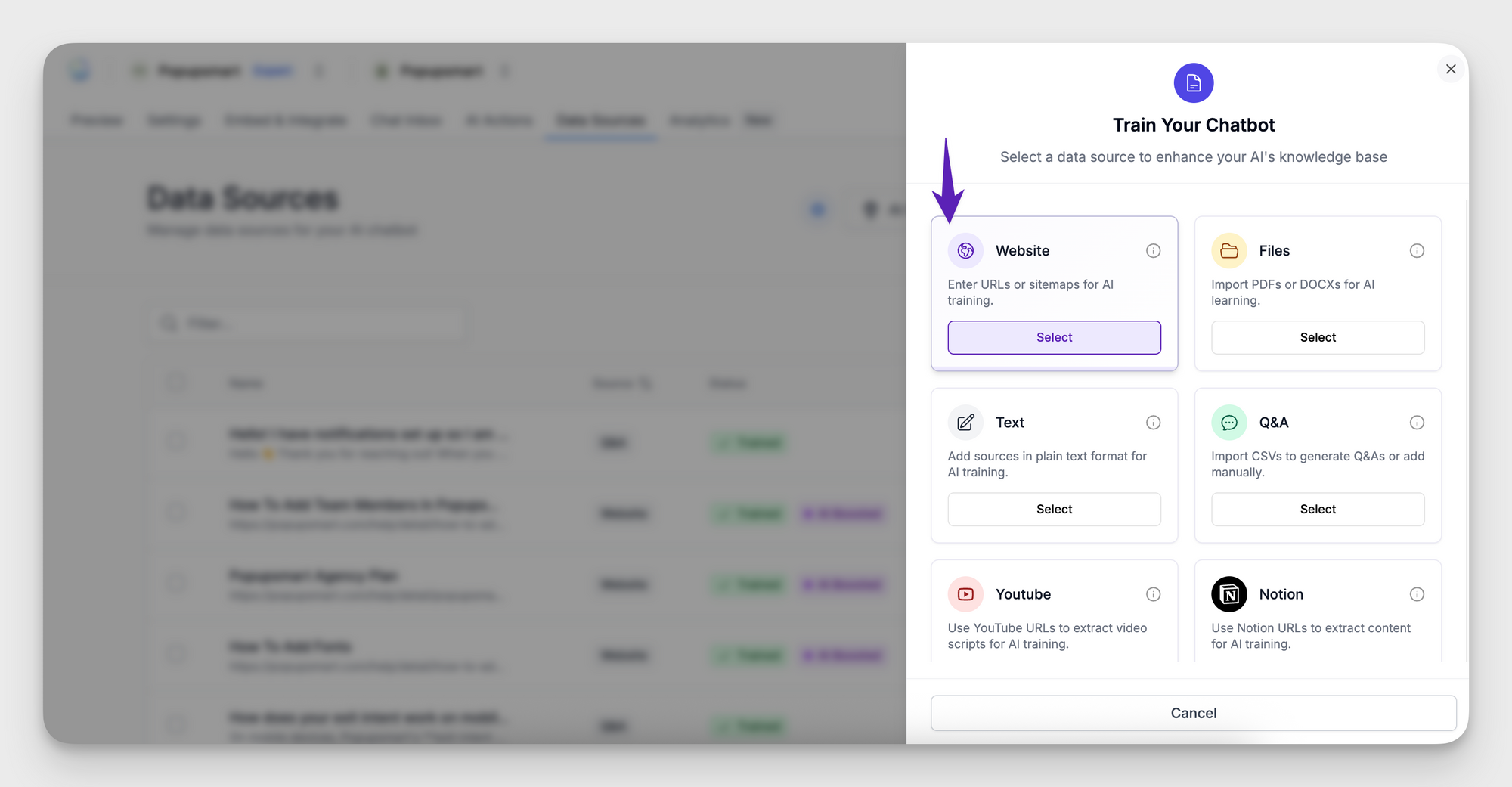
2. Choose a Crawl Type
3. Enter the URL and select Crawl pages
- LiveChatAI processes up to 2,500 pages per crawl.
- Crawling runs in the background, so you can continue working elsewhere in the dashboard.
4. Monitor Progress
The status column moves through three stages:
Crawling → Training → Trained
AI Boost is applied automatically to every crawled page.
5. Test Your Bot
Open Preview and ask questions that should be answered by the newly added pages. Confirm responses are correct.
Best Practices
FAQ
How long does a 2 500-page crawl take?
Typically five to twenty minutes, depending on page size.
Can I delete individual pages later?
Yes. Open the Website source, select the pages, choose Delete, then retrain the bot.
Does AI Boost cost extra?
No. It is built-in and always on for Website sources.
Why did a page fail to import?
The page must be publicly accessible, under roughly 2 MB of HTML, and not blocked by robots.txt.
Need assistance? Email [email protected] with the URL you’re trying to crawl.